|
|
Partie 2
L'interface de Visual Studio
Après avoir fait (très brièvement) connaissance des concepts
de la programmation objet, nous allons dans ce chapitre nous
familiariser avec l'interface C#, c'est-à-dire avec les
principaux outils que nous offre l'environnement de
développement Visual Studio. « Oui, mais c'est quand
qu'on commence à programmer ? » Ça vient, ça
vient, patience...
1. Structure des applications
1.1 Les fichiers sources
La première chose à faire, c'est d'assimiler l'architecture
des édifices que nous allons créer et le vocabulaire qui va
avec. Et ça, ce n'est pas rien, tant la structure des fichiers
sources d'une application C# a une fâcheuse tendance à
ressembler aux plans d'une usine à gaz. Mais enfin, pas le
choix, et autant consacrer quelques minutes à se mettre les
idées au clair plutôt que perdre ensuite des heures juste
parce qu'on s'est mélangé les pinceaux dans les arborescences
et les dénominations.
Alors, une application C#, c'est quoi ?
C'est, pour commencer, un ensemble de fichiers formant ce
qu'on appelle le code source, écrit
en... C#. En voilà une surprise.
La globalité d'une application C#, qui comprend l'ensemble
des fichiers source, s'appelle une solution.
Lorsqu'après avoir créé un Nouveau projet,
on souhaite Enregistrer tout, C#
demande pour notre solution un nom
et un répertoire :
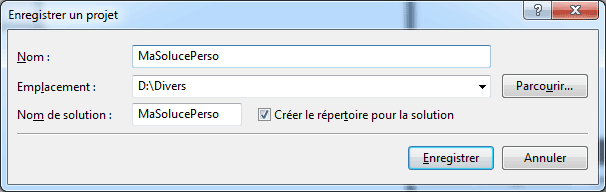
Aussi sec, Visual Studio va alors faire trois choses :
- créer à l'emplacement indiqué le répertoire portant le nom
de la solution.
- dans ce répertoire, toujours avec le nom de la solution,
créer un fichier *.sln contenant
les informations de la solution, c'est-à-dire l'ensemble de
l'arborescence des fichiers qui la constituent.
- dans ce même répertoire, créer un sous-répertoire
contenant les fichiers sources proprement dits.
Mais ce n'est qu'un combat, continuons le début. En effet,
une solution C# est seulement un conteneur pour nos
véritables applications, c'est-à-dire pour nos projets.
Si on le souhaite, une même solution peut contenir plusieurs
projets. Des dizaines, si on veut - pas sûr que ce soit une
bonne idée... Nous appliquerons donc une règle simplificatrice
et adopterons pour principe de ne jamais mettre qu'une seule
application (un seul projet) dans chaque solution. On
considèrera donc, en tant que débutants, qu'une
application C# = un projet = une solution.
Visual Studio va mettre dans le répertoire de la solution
toute une série de fichiers correspondant aux différents
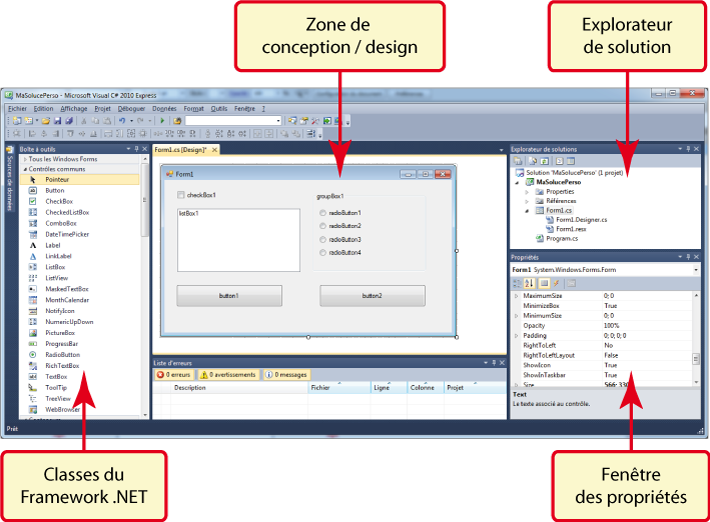
éléments de notre projet. Nous pouvons voir « de l'intérieur
cette arborescence, dans une des fenêtres de Visual Studio l'explorateur de solutions (a priori, en
haut à droite de l'écran) :
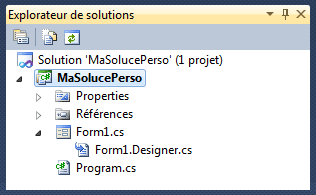
Chaque projet contient un certain nombre d'éléments de base,
dont les principaux sont des Form
(ou « formulaires »). Une application Windows basique compte
un seul formulaire, une application complexe peut en
rassembler plusieurs dizaines. Chaque formulaire est
sauvegardé dans un fichier différent, dont l'extension est *.cs. C'est dans ces fichiers *.cs que se
trouve le code proprement dit, celui-là même que vous allez
concevoir à la sueur de votre front altier et entrer dans la
machine de vos petits doigts graciles.
Quand je dis qu'à chaque Form correspond un fichier *.cs, en
réalité, ce n'est pas tout à fait vrai. C'est même
complètement faux, car une Form donne toujours
lieu non pas à un, mais deux fichiers *.cs.
En effet, lorsque nous allons concevoir (« designer »)
la Form, nous allons poser dessus à la souris des tas de tucs
et de bidules : des boutons, des listes, des cases à cocher,
etc. Eh bien, à tout ce que nous allons faire à la souris
correspondent des lignes de codes C# que Visual Studio écrit
pour nous dans un fichier spécial, NomDeLaForme.Designer.cs.
Ce fichier contient donc le code qui génère les éléments présents au lancement
de notre application, et que nous pouvsn donc visualiser de deux manières :
soit en allant voir ce code lui-même, soit en les visualisant sous
forme graphique, ce qu'on appelle le mode Design.
A priori, nous ne sommes pas censés aller trifouiller dans
ce code en réalité, cela s'avère régulièrement nécessaire, ne serait-ce que
pour corriger certaines erreurs engendrées par des manipulations apparemment anodines.
1.2 La compilation et l'exécutable
En ce qui concerne l'exécutable, à la différence de certains
autres langages, C# ne produit pas un code directement
exécutable par toutes les machines. Les instructions contenues
dans un exécutable C# sont écrites dans un langage appelé MSIL, pour MicroSoft Intermediate
Langage. Comme son nom l'indique, ce langage s'adresse à des
couches « intermédiaires » de la machine, à savoir un logiciel
poétiquement appelé le Framework .NET
(qu'on peut traduire par « infrastructure .NET »).
C'est ce Framekork .NET qui, à chaque exécution, va procèder à
une seconde compilation, afin de produire un authentique
exécutable.
L'idée de ce découpage, c'est de permettre à un même code de
n'être pas seulement valide sous Windows, mais aussi sous
MacOS ou sous Linux : il suffira que ces systèmes possèdent un
Framework .NET propre, effectuant ainsi une seconde
compilation différente, adaptée au système d'exploitation
concerné. Moui, ça c'est la théorie. En pratique, hélas, c'est
un peu moins vrai.
Tours est-il que Visual Studio nous offre deux voies
différentes pour produire des exécutables, chacune
correpondant à un besoin particulier.
- la voie la plus simple consiste à appuyer sur le bouton
d'exécution (un triangle vert) ou sur la touche F5.
Un exécutable est alors créé dans le sous-répertoire Bin/Debug de l'application. On peut
dire, pour faire simple, qu'il s'agit d'un exécutable
provisoire (mais très bien quand même).
- une fois l'application terminée, on peut engendrer un
exécutable définitif (c'est-à-dire, optimisé), avec la
commande Déboguer - Générer la solution
(touche F6). Un exécutable est
alors créé dans le sous-répertoire Bin/Debug.
À notre niveau, les différences entre l'une et l'autre
méthode sont largement au-delà de nos préoccupations. On ira
donc au plus facile, et on génèrera nos éxécutables par la
méthode la plus simple, à savoir la première.
2. Prise en main
Bien sûr, on pourrait écrire l'intégralité de nos
applications C# avec un simple bloc-notes, et n'avoir recours
à Visual Studio que pour la compilation. Mais franchement, ce
serait moche, tant Visual Studio nous offre une interface
destinée à faciliter de mille manières l'écriture de nos
applications. Petit tour du propriétaire.
2.1 Les deux fenêtres principales
Un développement via Visual Studio, va toujours marier deux
angles complémentaires.
- l'aspect graphique, visuel, de l'application. Bref, son
interface. La fenêtre dite Concepteur de
vues (on peut également parler de Design,
propose de disposer par des cliquer-glisser les différents
éléments de ladite interface. On pourra facilement les
redimensionner, les déplacer et, plus généralement,
spécifier toutes leurs propriétés par défaut. On le verra
bientôt, c'est également à partir de cette interface qu'on
va pouvoir prévoir les réactions de ces différents éléments
aux actions de l'utilisateur... mais n'anticipons pas !
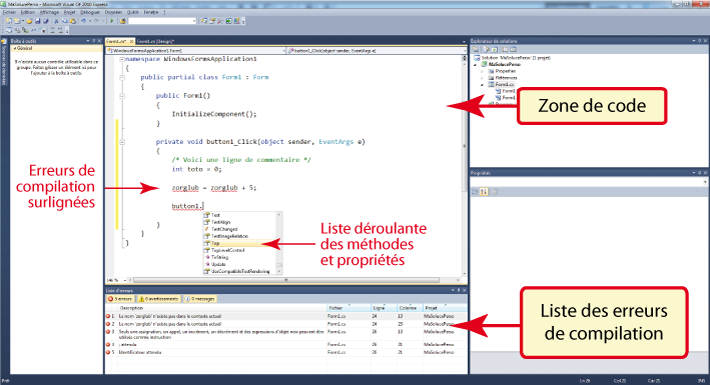
- le code proprement dit, où nous
allons entrer les différentes procédures en rapport avec le
formulaire en question (on remarque les nombreuses facilités
qu'offre Visual Studio, en particulier pour signaler en
temps réel au développeur toutes les erreurs de
compilation) :
Pour bâtir une application à interface Windows en C#, il nous
faudra effecuter de fréquents allers-retours entre les deux
représentations. Pour cela, rien de plus facile. On peut, au
choix, passer par le menu Affichage,
et choisir ensuite Code ou Concepteur
- à noter que ce même choix est aussi accessible via un clic
droit sur Form.cs dans
l'explorateur de solutions. On peut aussi utiliser les
raccourcis F7 (code) et Maj+F7
(concepteur)... ou tout bêtement, les onglets situés dans la
partie haute de l'écran.
2.2 Créer des contrôles à partir des classes du Framework .NET
 Définition : Définition :
Un contrôle est un objet créé à
partir de certaines classes définies dans le Framework .NET,
et qui possède la capacité à réagir aux actions de
l'utilisateur.
Tous les contrôles sont donc des objets, mais tous les
objets ne sont donc pas des contrôles... même si ce sera le
cas pour l'énorme majorité de ceux que nous utiliserons ici.
Visual Studio propose une boîte à outils,
où figurent, répartis en différentes catégories, les classes
les plus usuelles du Framewrok .NET.
Créer des contrôles à partir de ces classes afn de les
utiliser dans une application est extrêmement simple. Il
suffit d'aller piocher d'un clic de souris la classe voulue
dans la boîte à outils et d'effectuer un cliquer-glisser sur
le formulaire pour donner au contrôle la taille et
l'emplacement souhaités.
Par la suite, on peut toujours modifier l'emplacement et la
taille d'un contrôle, d'un simple coup de souris bien placé,
et naturellement, le supprimer d'un simple coup de SUPPR.
Si l'on veut manipuler plusieurs contrôles du formulaire à la
fois, on peut sélectionner toute une zone (par un habile
cliquer-glisser), ou encore sélectionner individuellement
chaque contrôle en maintenant la touche CTRL enfoncée. Bref,
que du très banal pour les utilisateurs avertis de Windows que
vous êtes.
 Remarque
avisée : Remarque
avisée :
Lorsqu'on crée ainsi des contrôles par de simples clics de
souris, en réalité, on écrit du code - ou, plus
exactement, on fait écrire automatiquement du code par C#. Nos
clics de souris sont en effet illico traduits en ligne de code
qui seront exécutées à chaque lancement de notre application,
lignes de code qui se trouvent dans le fichier
FormXX.Design.cs.
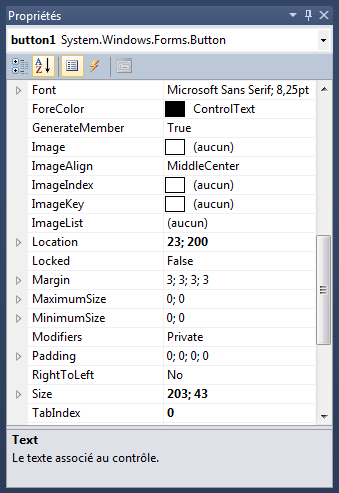
2.3 La fenêtre des propriétés
Chaque fois qu'un contrôle est sélectionné, la fenêtre
des propriétés (située en standard en bas à droite de
l'écran) affiche la liste des valeurs associées à ce contrôle.
C'est-à-dire que se mettent à jour la liste
des propriétés (qui comme on l'a vu varie d'une
classe, donc d'un contrôle, à l'autre) et la valeur
de ces propriétés (qui varie d'un contrôle à l'autre,
même lorsqu'ils sont de la même classe).
Les propriétés qui sont affichées là sont les propriétés
par défaut du contrôle. Autrement dit, ce sont celles
qu'aura le contrôle au lancement de
l'application. Bien sûr, par la suite, rien n'empêche
que ces propriétés soient modifiées, que ce soit par certaines
actions de l'utilisateur ou par des lignes de code (c'est même
un des principaux objectifs des lignes de code, quand on y
réfléchit bien).
2.4 Premières procédures évènementielles
En programmation événementielle, avant de taper quelque
groupe d'instructions que ce soit, il
faut se demander à quel moment ces instructions doivent être
exécutées, c'est-à-dire dans quelle procédure elles
doivent figurer. Là, deux possibilités.
- Ou bien ces instructions doivent être exécutées
indépendamment des actions de l'utilisateur. On est alors
dans le cadre traditionnel de la programmation procédurale :
elles figureront dans une procédure qui sera déclenchée par
un appel de code. À ce moment-là, on écrit soi-même sa
procédure, sous la forme :
Private void
NomDeProcédure()
{
...
}
- Ou bien nos instructions doivent figurer dans une
procédure événementielle,
c'est-à-dire une procédure qui devra s'exécuter suite à une
action donnée de l'utilisateur sur un contrôle donné. Dans
ce cas, il va falloir que C# « comprenne » que telle action
sur tel contrôle doit déclencher cette procédure. On verra
plus loin quelle instruction permet de réaliser cela. Pour
l'instant, on va se contenter d'obliger C# à le faire, sans
se préoccuper de la manière dont les choses se passent en
coulisses.
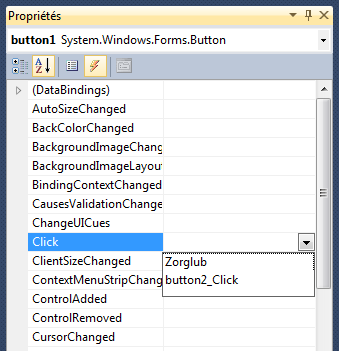
Le plus simple est d'utiliser l'interface de la fenêtre de
propriétés ; plus précisément, le bouton « éclair »
(événements). Si nous voulons que le clic sur un bouton
déclenche quelque chose comme l'apparition d'un message, alors
:
- on crée le bouton – admettons qu'il s'appelle button1
- on le sélectionne
- dans la fenêtre des propriétés, on fait apparaître
l'onglet des événements par le bouton « éclair »
- on choisit l'événement Click
- on double-clique...
On se retrouve alors dans la fenêtre de code ; C# vient
d'écrire une procédure vide, qui possède la tête suivante :
Private void
button1_Click(object sender, EventArgs e)
{
...
}
Nous venons donc de créer une
procédure qui se déclenchera chaque fois que l'utilisateur
cliquera sur le bouton button1.
On aura l'occasion de revenir sur les signes cabalistiques
qui se trouvent entre les parenthèses. Pour le moment,
contentons-nous de ne surtout pas y toucher. La première chose
à comprendre, c'est que Le lien entre
l'événement et la procédure n'a rien à voir avec le titre de
la procédure. Si C# a appelé celle-ci button1_Click,
c'est simplement pour nous aider à nous y retrouver. Mais cela
n'a rien d'obligatoire. Renommons la procédure, en lui donnant
par exemple comme titre Zorglub. Ce
faisant, nous avons cassé le lien entre l'action de
l'utilisateur et la procédure. Pour le rétablir, rien de plus
simple : il suffit de retourner dans la fenêtre des proprités,
dans l'onglet des événements. Ouvrons la liste déroulante qui
est en face de Click... et choisissons, dans la liste des
procédures proposées, Zorglub :
Et c'est reparti aussi sec, comme si de rien n'était.
2.5 L'éditeur de code
Pour finir, quelques mots sur le code et sur Visual Studio
qui, dans sa grande magnanimité, fait au mieux pour nous
faciliter la vie. Celui-ci va en effet décrypter notre code au
fur et à mesure de sa rédaction, et nous donner en temps réel
des indications via un système de couleurs, comme on peut le
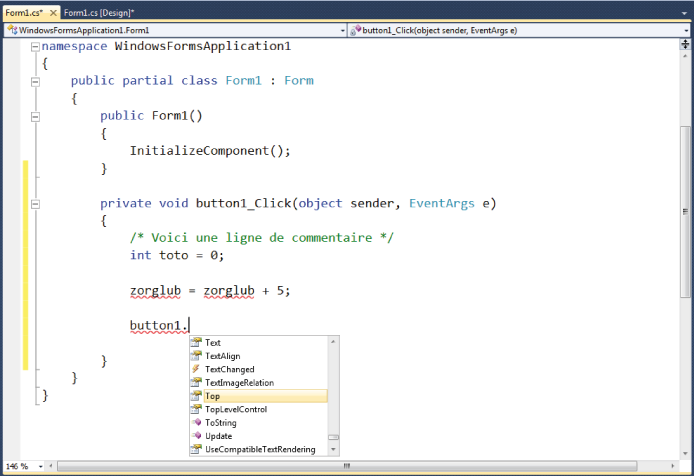
voir sur l'image ci-dessous :
Ainsi, sans qu'on ait même besoin de remuer une
oreille :
- les titres de procédures et les mots-clés du langage
seront automatiquement écrits en différentes nuances de bleu
- les commentaires seront automatiquement en vert
- toute ligne comportant une faute de syntaxe, ou posant un
problème au compilateur, sera immédiatement soulignée
d'un zigzag rouge. En amenant le curseur de la
souris au-dessus de l'erreur, la raison en sera
immédiatement affichée dans une bulle d'aide (mais aussi,
hélas, dans un vocabulaire souvent incompréhensible, il ne
faut pas rêver non plus).
- tout nom d'objet reconnu (ici, button1) suivi d'un point
fera apparaitre une liste déroulante
comportant l'ensemble des propriétés et méthodes accessibles
pour cet objet. Ce qui veut dire, inversement que si, lors
de la frappe du point qui suit un nom d'objet, aucune liste
déroulante n'apparaît, c'est que cet objet n'est pas reconnu
par le langage : soit que son nom a été mal orthographié,
soit qu'on parle d'un objet inexistant... De toutes façons,
c'est un signal d'alarme qui dénote un problème !
- Enfin, comme nous sommes dans un langage structuré, le
code est organisé sous forme de blocs
qui peuvent être déployés ou masqués, pour plus de
lisibilité, via les petites icônes carrés placés à gauche de
la tête de chaque bloc.
Voilà. Le décor est planté. Place aux premiers personnages...
|